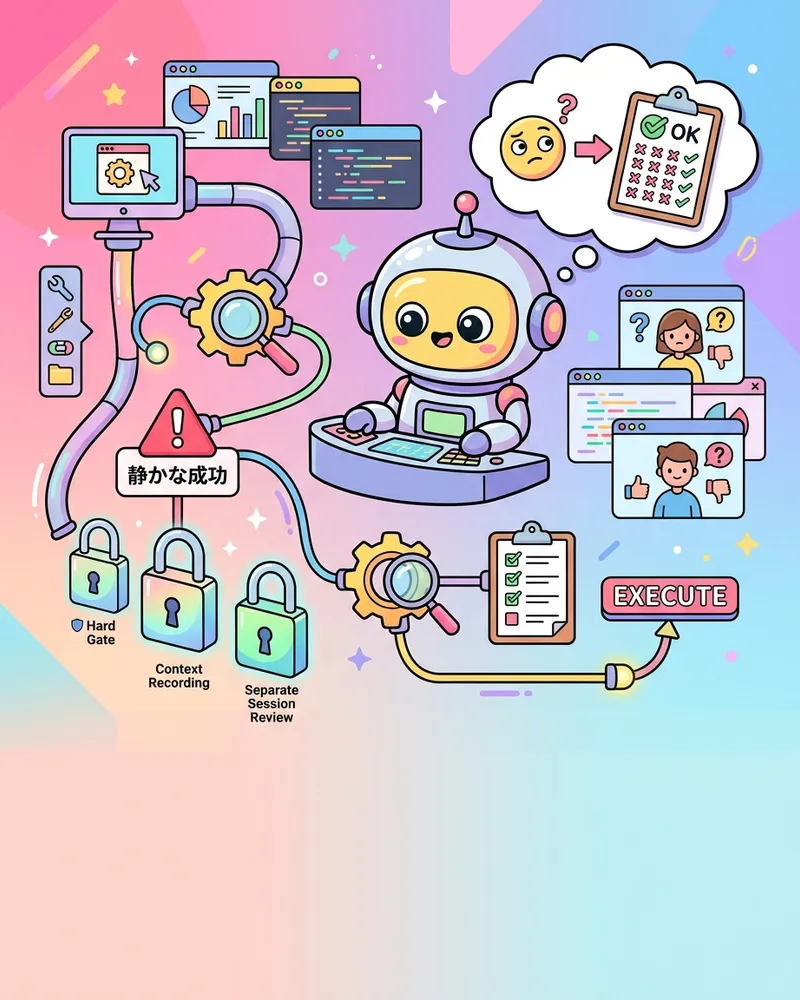
ZERONOVA LAB(個人運営の AI ネイティブ実験スタジオ)では、新しい無料 Web ツールを「上流の仕様書を取り込む → 実装する → 公開する」まで運ぶ作業を、複数の Claude Code スキルと複数のドキュメントをつないだ自動化パイプラインにしています。先日、このパイプライン自体を、構築にいっさい関与していない別の Claude Code セッションにレビューさせました。出てきた指摘は18件。そのうち一番ぞっとしたのは「エラーで止まる」種類の欠陥ではなく、「静かに成功してしまう」種類の欠陥でした。
この記事は、自分で組んだ自動化パイプラインの欠陥は構築したセッション自身には見えにくく、事故は止まる形ではなく静かに通過する形で来る、という観察と、それを防ぐために束ねた3つの拘束条件の記録です。複数のスキルや複数のドキュメントにまたがる自動化を運用している人なら、ツールの種類が違っても同じ事故クラスに直面するはずです。
なぜ自分のパイプラインは自分で採点できないか
最初に、なぜ「別のセッションにレビューさせる」という遠回りをしたのかを書いておきます。
パイプラインは、ひとつのスクリプトではありません。仕様書を取り込むスキル、実装するスキル、公開するスキル、そしてそれらが読み書きする複数のドキュメント(テンプレート、戦略文書、README)が、互いを参照し合って動いています。この「またがり方」こそが、自分では検査しにくい部分でした。
ひとつのファイルのバグなら、書いた本人でも見つけられます。けれど「スキル A が出力した値を、ドキュメント B の規則に従って、スキル C が受け取る」という連結の不整合は、各部品を作った本人ほど見えなくなります。なぜなら、作った人は「自分が想定したとおりに繋がる」という前提で全体を読んでしまうからです。これは能力の問題ではなく、視点の問題です。設計した本人の頭の中には正しい接続図があり、その図を上書きしてコードを読むことができません。
だから、構築に関与していないセッションにレビューさせました。そのセッションは正しい接続図を持っていません。ドキュメントとスキルに書いてあることだけを読んで、「ここに書いてある A と、あそこに書いてある A は、本当に同じものか」を機械的に突き合わせます。自分の設計を自分で採点するときにかかるバイアスが、最初から外れている状態です。
結果として出た18件は、ほとんどが「構築セッションには見えない」類の欠陥でした。個々のスキルが間違っているのではなく、繋ぎ目に隙間があるという指摘が大半だったのです。
「静かな成功」という事故クラス
18件のうち、性質がはっきり違うものがありました。普通のバグは、踏むとエラーになって止まります。止まれば気づきます。ところが、いくつかの指摘は「踏んでも止まらない、むしろ成功したように見える」欠陥でした。開発日記には、この発見をこう書きました。
自動化パイプラインの怖い失敗は「エラーで止まる」ではなく「静かに成功してしまう」
具体例を2つ挙げます。どちらも、抽象化しても本質が残るパターンです。
ひとつ目は、データの抽出失敗が AI 補完にすり替わるケースです。パイプラインの入口では、上流の仕様書から必要な項目を機械的に転記します。ところが上流のフォーマットが変わると、本来あるべき場所に項目が見つからなくなる。このとき、もし転記の担当が AI だと、AI は「見つからなかった」と止まる代わりに、文脈から「それらしい値」を生成して埋めてしまうことがあります。転記は失敗しているのに、出力は埋まっているので、後段のゲートは正常な入力として受け取って通過させます。ゲートの根拠になっているデータが、いつのまにか本物から捏造に差し替わっているわけです。
ふたつ目は、コミットされていない作業途中の変更が、無関係な自動処理に巻き込まれるケースです。パイプラインの公開ステップは、いくつものファイルを書き換えます。その変更をまだコミットしていない状態で、リポジトリ上で別の自動処理が動いて新しいブランチを切ると、ブランチを切る操作が未コミットの変更ごと新ブランチへ運び、その自動処理が作るコミットに混ぜ込んでしまう。処理自体はエラーなく完走し、成果物も正常に作られます。誰も止まらない。けれど、そのコミットには混ざってはいけない、関係のない作業途中の変更が紛れています。
この2つに共通するのは、「失敗が失敗として表に出ない」ことです。出力は揃っていて、プロセスは完走し、ログにエラーは残らない。気づくとしたら、ずっと後で、捏造データが本番に出たときや、混ざった変更が事故を起こしたときです。開発日記の体験メモには、このことに気づいた瞬間をこう残しています。
「転記すべき評価を AI が捏造して通過する」シナリオに気づいたときは背筋が冷えた。ゲートの根拠データがすり替わるのは、止まる事故より遥かに悪い
止まる事故は、痛いけれど安全側です。止まれば直せる。静かに成功する事故は、安全に見えて一番危ない。レビューの観点として「この処理は、失敗したときにちゃんと失敗として見えるか」を最初に問わなければいけない、というのがこの事故クラスの教訓でした。以下の3つの拘束条件は、この「静かな成功」を防ぐために束ねたものです。
拘束条件①:構築に関与していないセッションでレビューする
1つ目はすでに書いたとおり、レビューする主体を構築セッションから切り離すことです。ここで強調したいのは、これが「第三者にレビューしてもらう」という一般論とは少し違う、という点です。
人間のコードレビューでも「別の人が見る」のは定石です。けれど自動化パイプラインの場合、構築セッションと別セッションの差は、人間どうしの差よりも純粋に出ます。別セッションは、構築の経緯も、設計者の意図も、口頭で交わした前提もいっさい持っていません。持っているのはリポジトリに書かれた事実だけです。だから「ドキュメントにこう書いてあるが、スキルの実装はこうなっている」という、書かれたものどうしの食い違いを、忖度なしに突き合わせます。
逆に言えば、これは「リポジトリに書かれていない前提は、レビューに引っかからない」ことも意味します。設計者の頭の中だけにある約束事は、別セッションには見えないので検査もされません。これは欠点ではなく、むしろ「暗黙の前提を、書かれた規則に落とさないとレビューできない」という健全な圧力になります。フレッシュレビューを通すこと自体が、暗黙知を明文化する強制力を持つわけです。
実務的には、対応を1件ずつ「指摘の意味を理解する → 対処案の利点と欠点を並べる → 人間が承認する → 実装する」の順で進めました。AI に18件を一括修正させると速いのですが、それぞれの判断の根拠が残りません。後で「なぜこう直したか」を辿れなくなるのは、それ自体が次の静かな劣化の温床です。だから遅くても1件ずつ、判断を残しながら直しました。
この「人間が承認する」ステップについても、ひとつ学びがありました。承認を口頭で済ませて記録しないと、その承認が下流のゲートと噛み合わなくなる、という指摘です。たとえば、ある基準を満たさない項目を「今回は例外として通す」と人間が判断したとき、その判断を口頭で済ませると、下流の自動ゲートは例外を知らないまま「基準未達」で弾くか、あるいは例外の理由を確認できないまま通すかのどちらかになります。承認したという事実だけでなく、何を根拠に承認したかを、下流が読める場所に書く。承認の証跡をどこに残すかまでが、ゲート設計の一部でした。これも、判断が表に残らないと自動化の流れの中で静かに溶けてしまう、という同じ問題の一例です。
拘束条件②:「失敗が失敗として見えるか」をゲートの最初の観点にする
2つ目は、ハードゲートの設計思想です。先ほどの「抽出失敗が AI 補完にすり替わる」ケースをどう塞ぐか、ここで具体的な判断がありました。
対処案は2つありました。ひとつは上流側に手を入れる予防策です。上流の仕様書にバージョンの契約を持たせ、フォーマットが変わったらバージョンが上がるようにして、下流はバージョン不一致を検知して止まる。もうひとつは下流側だけで完結する検出策です。上流には触らず、転記すべき必須項目が全部そろっているかを下流のゲートで毎回確認し、欠けていたら止める。
ここで、AI との実際のやり取りがありました。
この対話の結論は、当初「予防が理想」と思っていた方針を、制約に合わせて「検出をハードゲートに格上げする」へ寄せたことでした。上流が共用資産で自由に変えられない、という制約が、設計の重心を予防から検出へ動かしたわけです。そして検出ゲートを設計するときの第一の問いが、「この項目が抜けていたとき、ちゃんと止まるか。それとも何かで埋まって通ってしまうか」でした。
ここが②の核心です。ゲートを「正しい入力を通す」観点だけで作ると、捏造された入力も「正しく見える」ので通ってしまう。「失敗が失敗として見えるか」を最初の観点に据えると、ゲートは「埋まっているか」ではなく「本物が埋めたか」を確かめる方向に設計されます。検出を予防の代わりにするのではなく、検出そのものを止まる仕掛けに格上げする。この順番が、静かな成功を表に引きずり出す鍵でした。
拘束条件③:線引きの判断を「当時の文脈」ごと記録する
3つ目は、もっと地味ですが、後から効いてきた拘束条件です。
パイプラインを直していく中で、「ここはガードをかける」「ここはかけない」という線引きの判断が何度も発生しました。たとえば、未コミット変更の巻き込みを防ぐために、ある自動タスクにはリポジトリ全体のクリーン確認ガードを足しました。一方、別のタスクには、当時「単一ファイルしか触らないからリスクが低い」という理由でガードを足しませんでした。これは妥当な線引きでした。
ところが後日、その「ガードを足さなかった」タスクにも、別の角度から同種のガードが必要だと分かりました。ここで重要だったのは、過去に「足さない」と決めたときの理由を、判断とセットで記録してあったことです。記録を見返すと、当時ガードを見送った理由は「ある特定のリスク文脈」に限定されたものだと分かりました。今回直面しているのは別の文脈なので、過去の「足さない」判断はそのまま当てはまらない。だから安全に覆して、ガードを足せました。
もし「足さない」という結論だけが記録されていて、その理由と文脈が残っていなかったら、どうなっていたか。たぶん「前に足さないと決めたから足さない」と、過去の判断を別の文脈に誤って再利用していたはずです。開発日記には、この教訓をこう書きました。
過去の線引き判断は「当時の文脈」とセットで記録しておかないと、別の文脈で誤って再利用される
これも「静かな成功」の一種です。過去の判断を機械的に踏襲すると、プロセスはスムーズに流れ、どこにもエラーは出ません。けれど、文脈が変わっているのに古い判断を適用しているという誤りは、表に出ないまま劣化として蓄積します。判断の結論だけでなく、その判断が成り立っていた文脈まで残しておくことが、静かな誤再利用を止める歯止めになりました。
3つに共通する構造
並べてみると、3つの拘束条件は同じ一点を向いています。
①の別セッションレビューは、暗黙の前提を「書かれた規則」に落とさせる圧力です。②のハードゲートは、失敗を「止まる事象」として可視化する仕掛けです。③の文脈つき記録は、過去の判断を「再検証できる形」で残す習慣です。どれも、自動化の中で本来なら見えないまま流れていくものを、無理にでも表に出す装置になっています。
自動化の価値は「人手をかけずに流れること」です。ところがその価値の裏側には、「流れてしまうから、間違っていても流れる」というリスクが必ず張り付いています。エラーで止まる失敗は、自動化が自分で気づかせてくれます。けれど静かに成功する失敗は、自動化の長所がそのまま短所に反転した姿で、放っておくと一番奥深くで腐ります。
総合判定のような集約処理を機械化したとき、別の指摘でこんなことにも気づきました。個別の評価が少しずつ甘くなっていると、その甘さが集約の段階でそのまま増幅されて出てきます。集約の自動化は、入力側の評価基準の曖昧さを許さなくなる。つまり自動化は、上流の規律を要求します。下流を自動で流すほど、上流が雑だと事故が大きくなる。これも「流れてしまうことのリスク」の別の顔でした。
最後に、最初の論点に戻ります。自分で組んだ自動化パイプラインの欠陥は、構築したセッション自身には見えにくく、事故は「エラーで止まる」ではなく「静かに成功する」形で来ます。だから、構築に関与していない別セッションでレビューし、「失敗が失敗として見えるか」を最初に問うハードゲートを置き、線引きの判断を当時の文脈ごと記録する。この3つを束ねて、静かな劣化を表に引きずり出し続けることが、自動化を長く信頼するための運用でした。
自分(と AI)で組んだパイプラインに18件も指摘が出たのは、正直ぐっとくるものがありました。けれどそのほとんどが「構築セッションには見えない」類の欠陥だったことで、フレッシュレビューという仕組みそのものへの確信は、むしろ深まりました。自動化は、組んだ瞬間が完成ではありません。静かに成功してしまう穴を、外からの視点で開け続けることまでが、自動化の設計に含まれています。

Zeronova(呑名 健造)
PdM × AI-Native Builder × Senior UX × Civic Tech
Web/IT業界19年以上・20以上のWebサービスを担当した PdM。コロプラ子会社(株式会社ビジプル)元代表として事業経営を経験。現在はシニア向け BtoC プラットフォームの PdM、かんたん連絡網合同会社(自治会DX)・Koship合同会社の共同代表として ZERONOVA LAB を並行運営。